MapReduce and Dask: Parallel Processing of Inconveniently Large Datasets
A Brief Overview


As our world grows more connected than ever, the amount of data that we as a species generate is growing quickly. "How quickly?" you might ask: there was an estimated 44 zettabytes of data in the world at the beginning of 2020, and by 2025 it is estimated that there will be 175 zettabytes of data. For reference, that is a near quadrupling of the amount of data in 5 years and 175 trillion gigabytes of data total!
How can we as human beings possibly obtain usable insights from even a tiny fraction of such a staggering quantity of data? Many technological solutions have been developed to process and simplify our ever-growing quantity of data. In this article, I will discuss a computing model designed to do just that: MapReduce. I will also discuss a popular Python implementation of that model: Dask.
What is MapReduce?
MapReduce is a programming model developed by Google in 2004 for processing big data at scale. At its core, it consists of two sequential steps.
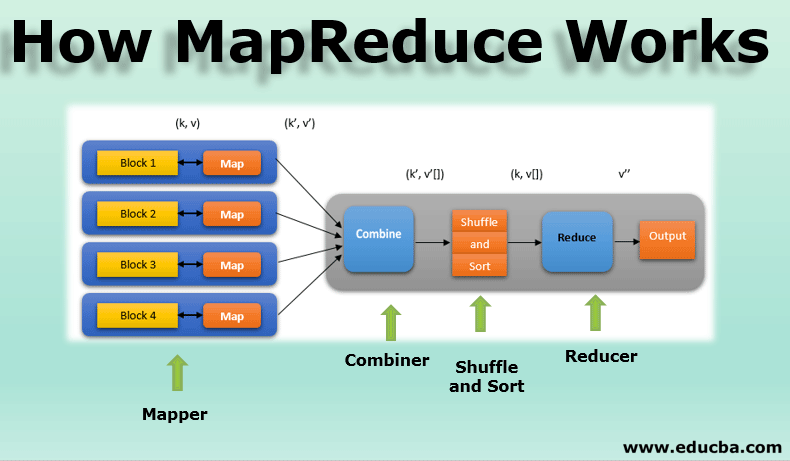
The first step is the mapping phase: in this phase, data is split into multiple chunks and processed in parallel across multiple nodes. These nodes can exist on a single machine or a cluster of machines, allowing the system to scale outwards on commodity hardware. During this phase, data can be filtered, sorted, processed, and otherwise manipulated into a more useful state.
The second step is the reducing phase. In this phase, the system performs a summarizing operation on each group, reducing the amount of data to a more usable size. for example, in this phase, averages, medians, and other combinations of the input data are calculated.
Most implementations of MapReduce include infrastructural code which coordinates the various servers, cores, and other nodes in the overall system, as well as managing communication between nodes and providing fault tolerance and redundancy should any nodes fail during processing.
Benefits of MapReduce
MapReduce presents a number of advantages over traditional data processing methods, such as:
Scalability: MapReduce is designed to work across multiple cores, processors, and machines. it allows users to combine the power of many smaller commodity processors towards a single task. this can result in substantial performance gains!
Fault Tolerance: orchestration and fallback code within MapReduce implementations allow tasks that fail or stall on a given node to be automatically assigned to a different node. Operations are atomic to ensure that conflicting results are not produced for the same input on more than one node.
Dask and MapReduce
Python is a popular language for those that work with data due to its simple syntax and extensive package library, which allows for rapid development and exploratory workflows with a relatively low investment of work. Popular tools for processing data at a high level in Python include numpyand pandas. Numpy is a library that wraps highly-optimized low-level (and sometimes hardware-optimized) C code that is used for the efficient processing of matrices and multidimensional arrays. Pandas is a higher-level library that wraps numpy in a container called a dataframe, with a convenient API while extending its capabilities. These libraries are powerful and easy to use, but neither of them are designed to operate in a distributed computing environment by default, that is where dask comes in to play.
Dask is a flexible parallel computing library for Python. Designed for scientific and analytical workloads, It has tight integration with pandas and numpy, allowing for high-level access to distributed computing. dask can scale across multiple cores, processors, and machines, and can also allow users to process data that can not easily or comfortably fit into memory.
With such capabilities, dask is more than capable of implementing MapReduce workflows on Python data. Most impressively, it can implement these operations with minimal code.
In fact, in many cases, a user can perform their operations as if they were working on a smaller dataset, which fits comfortably in memory. In the wonderful example provided by the free online course Practical Data Scientist, the user is able to process a 98GB CSV (compressed!) file of pharmaceutical shipments to determine the largest number of pills in a single shipment in 4 operations.
This example begins by dividing the source data across automatically-calculated chunks, filtering by shipments that contain pharmaceutical tablets (mapping), and calculating the maximum total dosage units of that shipment (reducing). It performs these operations in a lazy way, waiting until the dask data frame has all operations queued up, automatically optimizing operations, and only executing code when necessary. The code looks like this:
# source data can be downloaded at the following location. you will need to extract the data manually to your project root folder
#https://www.dropbox.com/s/oiv3k3sfwiviup5/all_prescriptions.csv?dl=0
import dask.dataframe as dd
# Mapping phase, reads the data and automatically divides into chunks, also performs filtering
df = dd.read_csv(
"arcos_all_washpost_2006_2012.tsv",
sep="\t",
dtype={
"ACTION_INDICATOR": "object",
"ORDER_FORM_NO": "object",
"REPORTER_ADDRESS2": "object",
"REPORTER_ADDL_CO_INFO": "object",
"BUYER_ADDL_CO_INFO": "object",
"BUYER_ADDRESS2": "object",
"NDC_NO": "object",
"UNIT": "object",
},
)
df = df[df["Measure"] == "TAB"]
# Reduce phase, where dask automatically calculates the max dosage unit of each chunk.
max_shipment = df["DOSAGE_UNIT"].max()
max_shipment.compute()
# outputs 3115000.0
With just those few lines of code, a user can process a truly massive dataset in parallel, with a high-level, easy-to-read API. What a world we live in!
Map-Reducing the Complexity
With modern tools like dask, the power of MapReduce is available to regular users, and the daunting task of obtaining insight from the massive flow of data our modern world generates is a little less daunting. Who knows what the future will bring?